어려운 수학 정리
22 Jun 20211. 뤼카의 정리 (Lucas’ Theorem)
음이 아닌 정수 n, k와 작은 소수 p가 주어졌을 때 n과 k를 p진수로 나타낸다고 하자.
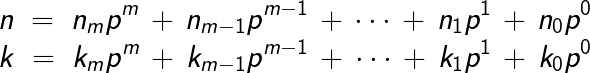
이 때 다음과 같은 식이 성립한다.
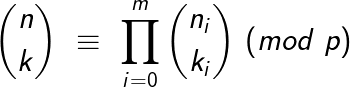
해당 식의 증명은 다른 분들에게 맡기고… 놀랍게도 기존의 이항계수를 구하는 알고리즘은 dp를 활용해 구하는 것이 대부분이었다. 하지만 n이 커질수록 필요로하는 array의 크기도 커지고 걸리는 시간 역시 점점 늘어났다.
어차피 이항계수는 특정 범위를 넘어서면 자료형에 담을 수 없어 임의의 숫자로 나누어 준 나머지를 종종 구했다. 이 때 뤼카의 정리를 활용하면 nCk mod p 를 굉장히 빠른 시간내에 구할 수 있게 된다. 유의할 것은 ni 보다 ki가 크다면 그 때의 comb값은 0이 되도록 해야한다는 것이다.
- Lucas Algorithm
var n:Int64 = 1000000, k:Int64 = 10000, m:Int64 = 13
var comb:[[Int]] = Array(repeating: Array(repeating: 0, count: 2001), count: 2001)
comb[0][0] = 1
for i in 1...Int(m) {
comb[i][0] = 1
for j in 1...i {
comb[i][j] = (comb[i-1][j-1] + comb[i-1][j])%Int(m)
}
}
var result = 1
while n != 0 && k != 0 {
result *= comb[Int(n%m)][Int(k%m)]
result %= Int(m)
n /= m
k /= m
}
2. 확장 유클리드 알고리즘
두 수 A, B가 주어졌을 때 두 수는 다음과 같은 부정방정식의 해를 갖는다.
AX+BY = gcd(A, B)
이 때 해가 되는 X, Y를 구하는 알고리즘을 확장 유클리드 알고리즘이라 부른다. 확장 유클리드 알고리즘은 유클리드 알고리즘을 활용해 gcd를 구한것을 응용해서 해를 구한다.
유클리드 알고리즘에서 A = BQ + R 형태로 gcd를 구할 수 있던 것을 생각하자. 이 때 r1 = A, r2 = B로 초깃값을 주고 다시 식을 일반화하면 다음과 같이 변한다.
식 : r1 = r2Q + r -> r = r1 - r2Q
r1 = r2, r2 = r를 주고 반복
이를 반복해서 새롭게 구한 r이 0이 되었을 때 그 때의 r2의 값이 gcd가 되었었다.
이제부터 r을 r = sA + tB의 형태로 나타낼 것이다. 즉 r을 초기값인 A와 B의 방정식 형태로 나타내겠다는 의미이다. 유클리드를 통해 구하게 되는 gcd도 gcd(A, B) = sA + tB의 형태로 나타날 것이고 그 때의 s, t가 부정방정식의 해가 될 것이다. 그렇다면 s와 t를 어떻게 나타내면 좋을까?
r1 = s1A + t1B
r2 = s2A + t2B
초기에는 r1 = A, r2 = B이기 때문에 s1 = 1, s2 = 0, t1 = 0, t2 = 1로 초깃값을 준다. 그렇다면 r은 다음과 같이 변형할 수 있다.
r = r1 - r2Q = (s1A + t1B) - (s2A + t2B)Q
r = (s1 - s2Q)A + (t1 - t2Q)B = sA + tB
놀랍게도 r의 s와 t는 r과 동일한 형태로 나타나게 된다.
r = r1 - r2Q
s = s1 - s2Q
t = t1 - t2Q
이제 r1 = r2, r2 = r로 값을 바꿀 때 동일하게 s1 = s2, s2 = s, t1 = t2, t2 = t로 값을 바꿔준다. 최종적으로 gcd의 s와 t를 구해주면 문제를 해결할 수 있다.
- Euclidean Algorithm
func Euclidean(a: Int, b: Int) -> (Int, Int, Int) {
var r1 = a, r2 = b, s1 = 1, s2 = 0, t1 = 0, t2 = 1
while r2 != 0 {
let q = r1/r2
let r = r1-q*r2, s = s1-q*s2, t = t1-q*t2
r1 = r2
s1 = s2
t1 = t2
r2 = r
s2 = s
t2 = t
}
return (r1, s1, t1)
}
3. 중국인의 나머지 정리
다음과 같은 문제를 어디선가 본 적이 있을 것이다.
3으로 나누었을 때 2가 남고, 5로 나누었을 때 3이 남고, 7로 나누었을 때 2가 남는 수는 무엇인가?
이와 같은 연립방정식 문제를 쉽게 풀 수 있도록 도와주는 정리를 중국인의 나머지 정리라 부른다. 중국인의 나머지 정리는 다음과 같다.
m1, m2 … mn이 쌍마다 서로소이면 (gcd(mi, mj) = 1), 다음 연립 합동식
x ≡ a1 (mod m1)
x ≡ a2 (mod m2)
x ≡ a3 (mod m3)
⋅
⋅
⋅
x ≡ an(mod mn)
을 만족하는 유일한 해 x가 존재한다.
x가 유일하다는 점을 주목하자. 실제로 x를 구하는 방법은 다음과 같다.
모든 mi들의 곱을 m이라 정의하자. (m = m1m2…mn)
그 때 nk = m/mk 라고 했을 때 gcd(nk, mk) = 1이 된다.
이 때 유클리드 확장 알고리즘을 사용하면 sknk + tkmk = 1을 만족하는 sk, tk를 찾을 수 있다.
여기서 sknk ≡ 1 (mod mk)가 성립하게 된다.
최종적으로 x = a1n1s1 + a2n2s2 … annnsn 이라고 하자.
그러면 mk로 나누게 되면 k번째 항을 제외하고는 모두 나누어떨어져서
x ≡ aknksk ≡ ak⋅1 ≡ ak (mod mk) 를 만족하게 된다.
이 때 해 x는 m보다 작아야 하므로 x = a1n1s1 + a2n2s2 … annnsn (mod m)이 구하고자 하는 해가 된다.
- 중국인의 나머지 정리 Algorithm
func Euclidean(a: Int, b: Int) -> Int {
var r1 = a, r2 = b, s1 = 1, t1 = 0, s2 = 0, t2 = 1
while r2 != 0 {
let q = r1/r2
let r = r1-q*r2, s = s1-q*s2, t = t1-q*t2
r1 = r2
s1 = s2
t1 = t2
r2 = r
s2 = s
t2 = t
}
return s1
}
func Chinese(a: [Int], m: [Int]) -> Int {
let mult_m = m.reduce(1, *)
var x = 0
for i in 0..<a.count {
let n = mult_m/m[i]
let s = (Euclidean(a: n, b: m[i]) + m[i])%m[i]
x += n*s*a[i]
}
return x%mult_m
}
4. 밀러-라빈 소수판별법 (Miller-Rabin primality test)
밀러-라빈 소수 판별법은 N이 소수인지 아닌지를 확률적으로 알아내는 판별법이다. 밀러-라빈 소수 판별법을 알아보기 전에 2가지 보조정리를 알고 가야한다.
- 보조정리 1 : 페르마의 소정리
소수 p와 임의의 정수 a에 대해서 다음을 만족한다.
ap ≡ a (mod p)양변을 a로 나누어주면
ap-1 ≡ 1 (mod p) when a%p ≠ 0
- 보조정리 2
소수 p에 대해서 x2 ≡ 1 (mod p) 이면,
x ≡ -1 (mod p) 혹은 x ≡ 1 (mod p) 를 만족한다.
자 이제 밀러 라빈 소수판별법에 대해서 알아보자. 임의의 2가 아닌 소수 N에 대해서 N-1은 항상 짝수일 것이다.
N-1 = d*2r
그러면 임의의 정수 a와 소수 N에 대해서 다음을 만족한다.
aN-1 = adx2r ≡ 1 (mod N) by 보조정리 1
adx2r-1 ≡ -1 (mod N) or adx2r-1 ≡ 1 (mod N) by 보조정리 2
만약 보조정리 2를 적용한 결과가 -1 이 될 경우는 상관 없지만 1이 될 경우 반복적으로 보조정리 2를 적용할 수 있다. 따라서 최종적으로 N이 소수라면 다음의 2가지 조건 중 하나를 만족해야 한다.
- ad ≡ 1 (mod N)
- adx2r ≡ -1 (mod N) for some r
밀러라빈은 확률적으로 소수 여부를 확인해주는 알고리즘이라고 앞에서 얘기했었다. 실제로 N이 소수가 아니더라도 특정한 a에 대해서 이 조건을 만족시킬 수 있다. 따라서 우리는 최대한 많은 a에 대해서 알고리즘을 적용해 소수인지를 확인해주어야한다.
일반적으로 int 범위에 대해서는 a = [2, 7, 61] 세 소수에 대해서만 확인해주면 소수 여부를 정확히 판별할 수 있다. LongLong 범위에 대해서는 41이하의 소수에 대해 모두 확인해주면 소수 여부를 판별할 수 있다고 알려져 있다.
- Miller-Rabin Algorithm
let alist:[UInt64] = [2, 7, 61]
func powmod(x: UInt64, y: UInt64, m:UInt64) -> UInt64 {
var X = x%m
var iter = y
var result:UInt64 = 1
while iter != 0 {
if iter%2 == 1 {
result = (result*X)%m
}
X = (X*X)%m
iter /= 2
}
return result
//x^y (mod m)을 구해주는 함수
}
func miller(n: UInt64, a: UInt64) -> Bool {
var d = n-1
while d%2 == 0 {
if powmod(x: a, y: d, m: n) == n-1 {
// a^d (mod n)이 -1이 나오는 것은 n-1이 되는 것과 같다.
return true
}
d /= 2
}
let tmp = powmod(x: a, y: d, m: n)
return tmp == n-1 || tmp == 1
//최종적으로 홀수 지수가 남았을 때 1 혹은 -1이 되는지 모두 확인해준다.
}
func isPrime(n: UInt64) -> Bool {
if n <= 1 {
return false
}
for a in alist {
if !miller(n: n, a: a) {
return false
//하나라도 소수 조건을 만족하지 못하면 소수가 아니다
}
}
return true
//모든 a에 대해 소수 조건을 만족하면 소수라고 판정한다.
}
5. 폴라드 로 알고리즘 (Pollard’s rho Algorithm)
인수 분해 알고리즘으로 어떤 수 n의 인수를 한가지 찾을 때 사용하는 알고리즘이다. 유의할 점으로는 소인수 분해가 아니라 인수를 찾아주는 것이기 때문에 소인수 분해를 하고 싶다면 반복적으로 사용해야한다.
먼저 f(x) = x2 + c (mod n) 형태의 함수를 생각해보자. 그러면 초기값 x0에 대해 다음과 같이 수열을 정의하자.
xi = x0, f(x0), f(f(x0)) …
n = 24751043, x0 = 2, c = 1이라면 수열은 다음과 같다.
xi = 2, 5, 26, 677, 458330 …
이 때 각 항을 p|n인 p로 나눈 나머지를 구한다. 24751043 = 317 x 78079이기 때문에 p = 317로 수열을 나눈 나머지를 순서대로 써보자.
xi mod p = 2, 5, 26, 43, 265, 169, 32, 74, 88, 137, 67, 52, 169 …
위의 형태로 나타나게 되고 놀랍게도 이후로 [169, 32, 74, 88, 137, 67, 52]가 무한히 반복된다. 여담으로 이 형태가 마치 rho의 형태와 비슷하다고 하여 pollard’s rho라는 이름이 붙게 된 알고리즘이다.
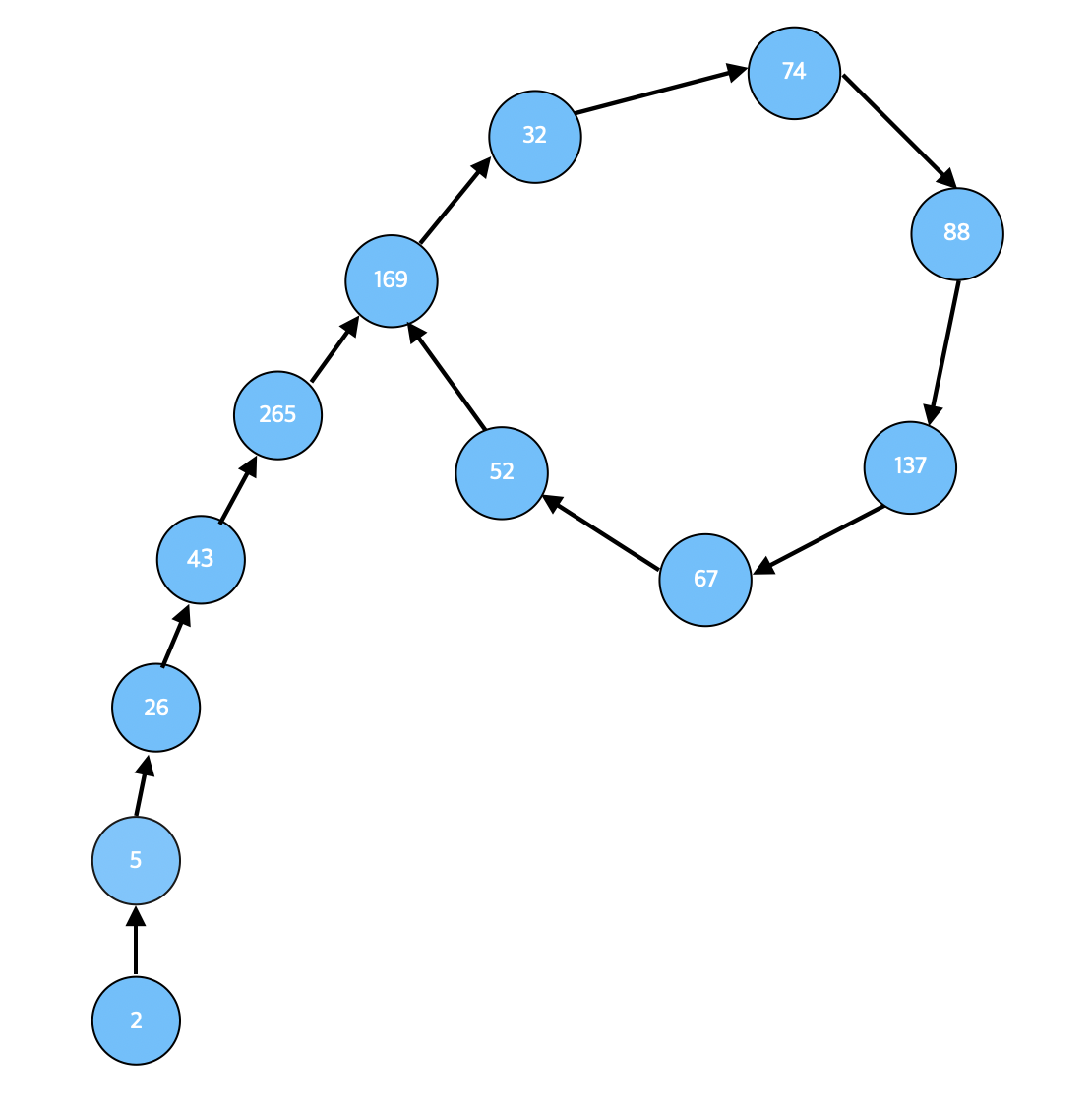
자 이제 수열상의 i < j인 두 index를 골랐을 때 다음을 만족한다고 하자.
xi ≡ xj (mod p)
이는 달리 얘기하면 p|(xi - xj) 라는 의미가 된다. 이 때 p는 n의 인수라고 가정했기 때문에 p|n이 성립하고 최종적으로 p|gcd(xi - xj, n)이 성립한다. 따라서 이를 활용하여 p값을 먼저 정하고 진행하는 것이 아니라 gcd(xi - xj, n) 값을 구하고 그 값이 1이 아닐경우 n의 인수 p라고 판별할 수 있다.
그렇다면 xi, xj를 선택하는 기준을 어떻게 잡아야할까? 일반적으로 알려진 방법은 xi = f(xi), xj = f(f(xj)) 로 값을 변경해가면서 gcd(xi - xj, n) 값이 1이 아닌 지점이 나올때까지 반복하는 형태로 사용한다. 왜 xi는 f를 한번 적용시키는데 xj는 f를 두번 적용시키는지에 대해 의문이 들 수 있다. 만약 두 수에 대해 f를 모두 한번씩 적용시키게 되면 다음과 같다.
f(xi) = xi2 + c (mod n)
f(xj) = xj2 + c (mod n)
이 때 xi ≡ xj (mod p) 이라면 f(xi) ≡ f(xj) (mod p) 가 성립하게 된다. 만약 gcd(xi - xj, n) = 1이 되었을 경우 xi, xj 모두 f를 한번씩만 적용하게 되면 gcd값이 계속 1이 나타나게 될 것이다. 이를 방지하기 위해 xi, xj의 f 적용 횟수에 차이를 두고 알고리즘을 구현한다.
- Pollard’s rho Algorithm
func phr(n: UInt64) -> UInt64 {
if isPrime(n: n) {
//miller-rabim 알고리즘으로 소수 판정을 빨리 함
return n
}
if n == 1 {
return 1
}
if n%2 == 0 {
return 2
}
var x:UInt64 = 2, y:UInt64 = 2, g:UInt64 = 1
//x0 = 2로 주고 시작했다. 임의의 숫자로 변경가능
let c:[UInt64] = [1, 2, 3]
//c에 대해서는 1, 2, 3에 대해 시도하도록 구현
for i in 0...2 {
x = 2
y = 2
g = 1
while g == 1 {
x = (mulmod(x: x, y: x, m: n) + c[i])%n
//x = x*x + c (mod n)을 수행
y = (mulmod(x: y, y: y, m: n) + c[i])%n
y = (mulmod(x: y, y: y, m: n) + c[i])%n
//y는 f를 두번 적용시킨다.
let tmp = x > y ? x-y : y-x
g = gcd(a: tmp, b: n)
}
if g != n {
break
}
}
return g
}
그런데 코드를 보면 알겠지만 시작부터 밀러 라빈 알고리즘으로 소수 판정을 해주는 것을 확인할 수 있다. n이 합성수가 아닌 소수라면 pollard-rho는 매우 느린 속도로 동작을 하게되기 때문에 소수일 경우 해당 값을 반환하도록 구현을 해놨다.
또한 x0와 c에 대해 여러 값을 시도해보도록 구현이 되어있다. x0와 c값에 따라 인수 분해가 불가능한 숫자들이 몇가지 있다. 이를 방지하고자 여러개의 초기값에 대해서 pollard rho 알고리즘을 적용시켜 인수를 찾아주도록 구현한 것이다.
추천 문제
백준 11402 이항 계수 4
백준 3955 캔디 분배
백준 15718 돌아온 떡파이어
백준 5615 아파트 임대