Suffix Array & LCP
22 Jun 20211. Suffix Array
suffix란 앞에서 배웠듯이 접미사들을 의미한다.
예를 들어 banana에 대해 접미사를 나열해보면 다음과 같다.
| Suffix | i |
|---|---|
| banana | 1 |
| anana | 2 |
| nana | 3 |
| ana | 4 |
| na | 5 |
| a | 6 |
이 접미사들을 사전 순으로 나열하면 다음과 같이 정리할 수 있다.
| Suffix | i |
|---|---|
| a | 6 |
| ana | 4 |
| anana | 2 |
| banana | 1 |
| na | 5 |
| nana | 3 |
이렇게 사전순으로 정렬된 i의 배열 [6, 4, 2, 1, 5, 3]을 S의 Suffix Array라고 부른다.
어떻게하면 suffix array를 구할 수 있을까? 단순히 정렬 알고리즘을 사용한다고하면 정렬에 O(nlogn) 비교에 O(n) 이 걸려 총 O(n2logn) 이 소요되게 된다. 이를 개선하기 위해서 O(nlog2n)만에 구하는 알고리즘이 존재하는데 이를 맨버-마이어스 알고리즘이라 부른다.
2. Manber-Myers Algorithm
글자 정렬을 할 때 1, 2, 4… 와 같이 2의 제곱수들을 기준으로 정렬하는 방식으로 되어있는 알고리즘이다. 예를들어 banana를 기준으로 정렬을 해보면 첫글자를 갖고 먼저 정렬을 하면 다음과 같다.
| 20 |
|---|
| anana |
| ana |
| a |
| banana |
| nana |
| na |
단순히 첫번째 글자만 비교하면 되니까 O(nlogn)이 걸린다.
이번에는 두개의 글자를 가지고 비교를 해보자.
| 21 |
|---|
| a |
| ana |
| anana |
| banana |
| nana |
| na |
이번에는 네개의 글자를 가지고 비교를 해보자.
| 22 |
|---|
| a |
| ana |
| anana |
| banana |
| na |
| nana |
어라 그런데 생각을 해보면 4개의 글자를 비교하는 과정에서 하나씩 비교를 하게되면 결국에는 O(n)만큼 비교를 하게 되는 것이 아닌가 생각이 든다. 결국 O(n2logn)이 걸리는 것은 변함이 없어 보인다. 이를 해결하기 위해 우리는 g와 sfx 배열을 이용할 것이다.
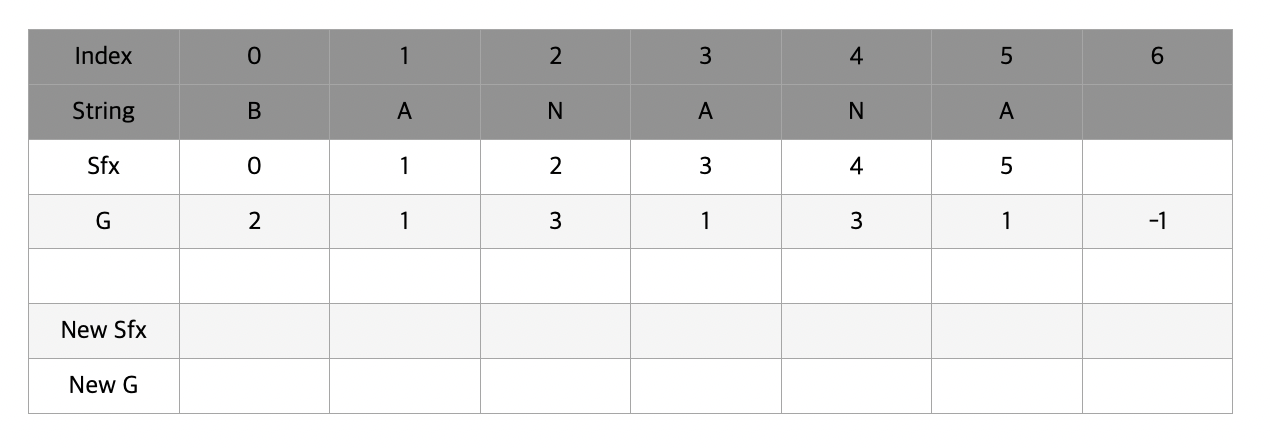
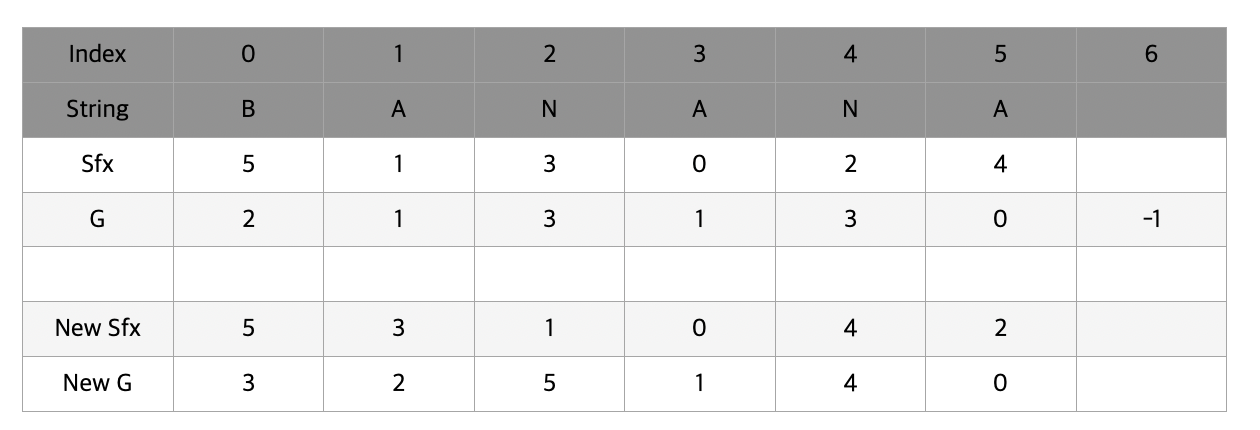
먼저 suffix 배열에는 각각 0번부터 5번까지 순차적으로 입력을 해주고 g에는 알파벳들의 순서에 맞게 번호를 매겨준다. banana의 경우 a가 1, b가 2, n이 3이 되었다. g 배열의 마지막 index에는 항상 -1을 넣어놓는다.
suffix 배열을 g를 기준으로 정렬할 것이다. 이 때 g는 해당 위치의 알파벳을 시작으로 t 길이의 영역간의 대소 순위를 나타내준다. 초기에는 t가 1이므로 b, a, n, a, n, a 각각에 대한 크기 순위가 g에 저장되어있다.
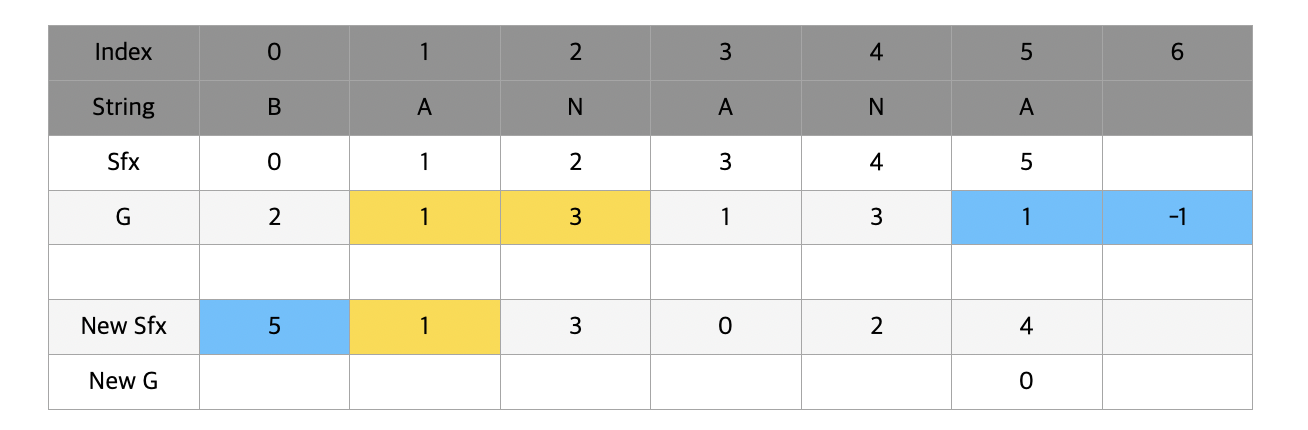
그렇게 새롭게 sfx배열을 얻어내면 위와 같이 나타난다. 우리는 새롭게 정렬된 sfx배열과 기존의 g 배열을 이용해서 새로운 g를 얻어낼 것이다. 새롭게 얻어내는 g는 이전 t의 2배에 해당하는 영역의 순위를 나타낸다. 즉 이번에는 ba, an, na, an, na, a 에 대해서 g값을 얻어낼 것이다.
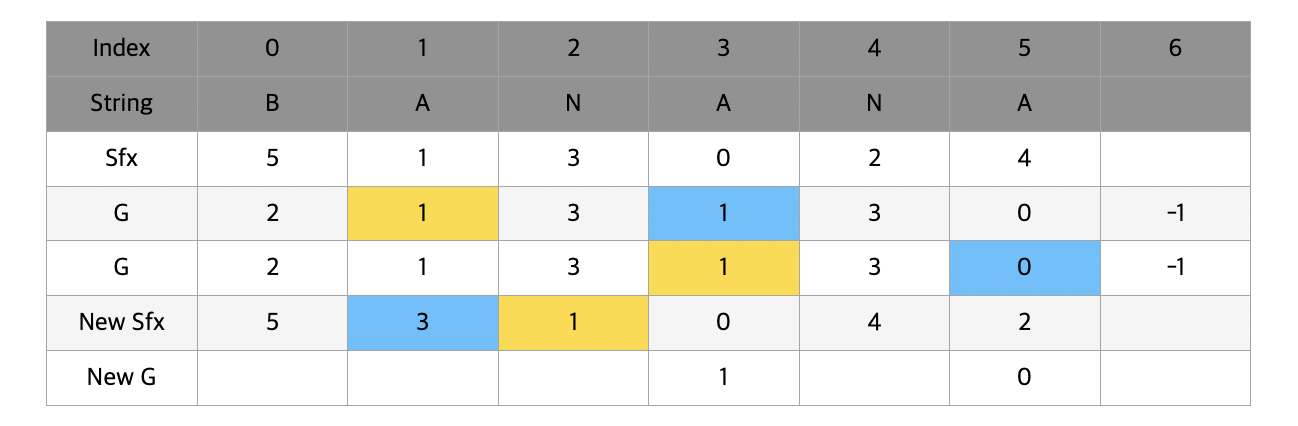
맨 처음에는 5번 index와 1번 index를 비교한다. 이 때 g[5]와 g[1]의 값은 똑같이 1(A)이 나왔기 때문에 t만큼 떨어진 위치의 알파벳을 확인해준다. t의 값은 아직 1이기 때문에 g[5+1] 과 g[1+1] 을 비교해주고 각각 -1(빈칸)과 3(N)이 나타난다.
-1을 g의 마지막 index에 대입해준 이유가 여기서 나타난다. 공백에 다른 모든 알파벳보다 우선순위를 주기 위해서이다. g[6] < g[2] 이기 때문에 new g[1]에 new g[5] + 1을 대입해주게 된다.
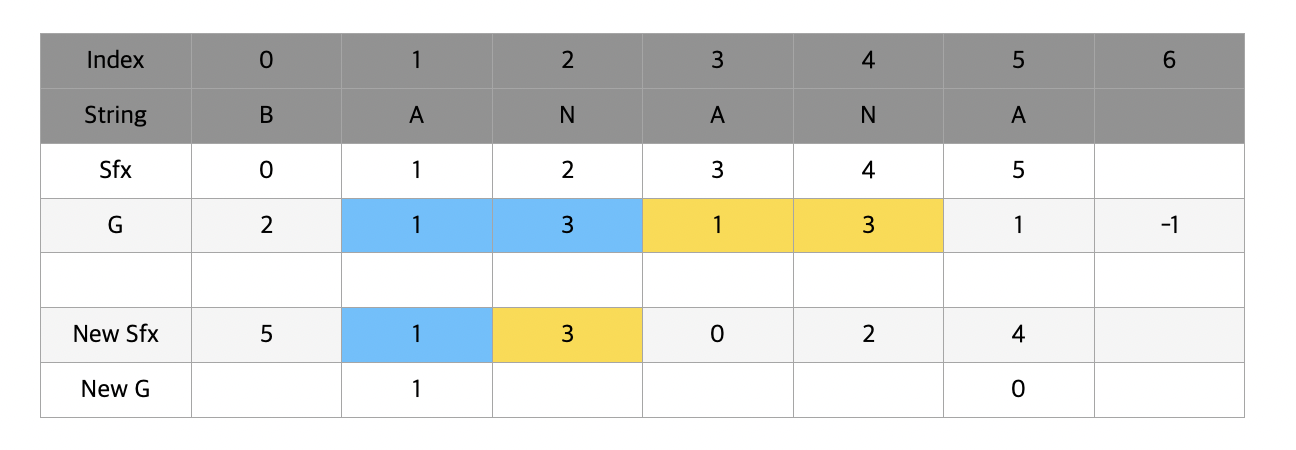
이번에는 g[1]과 g[3]을 비교할 차례이다. 하지만 g[1] == g[3] (A), g[2] == g[4] (N) 이기 때문에 new g[1] == new g[3] 가 되게 된다.
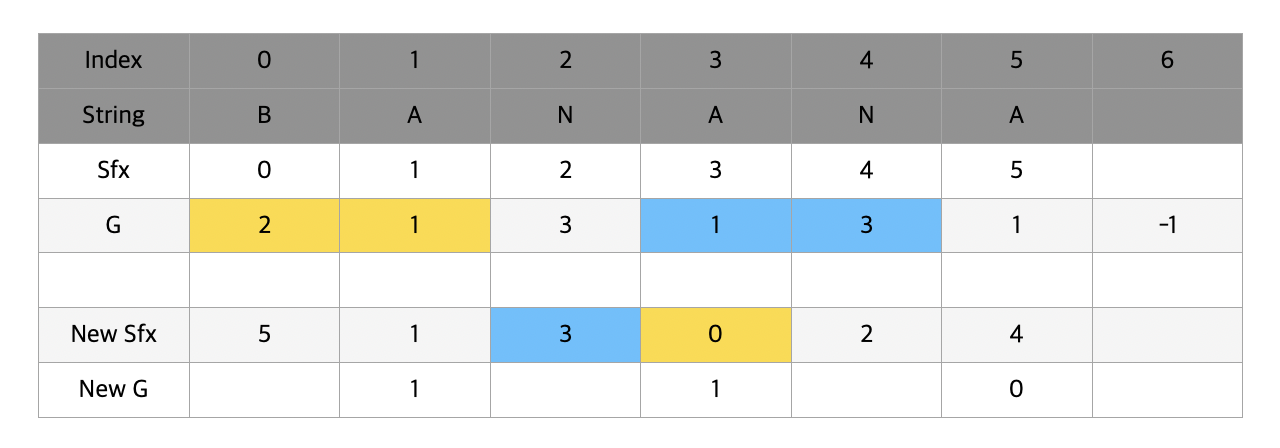
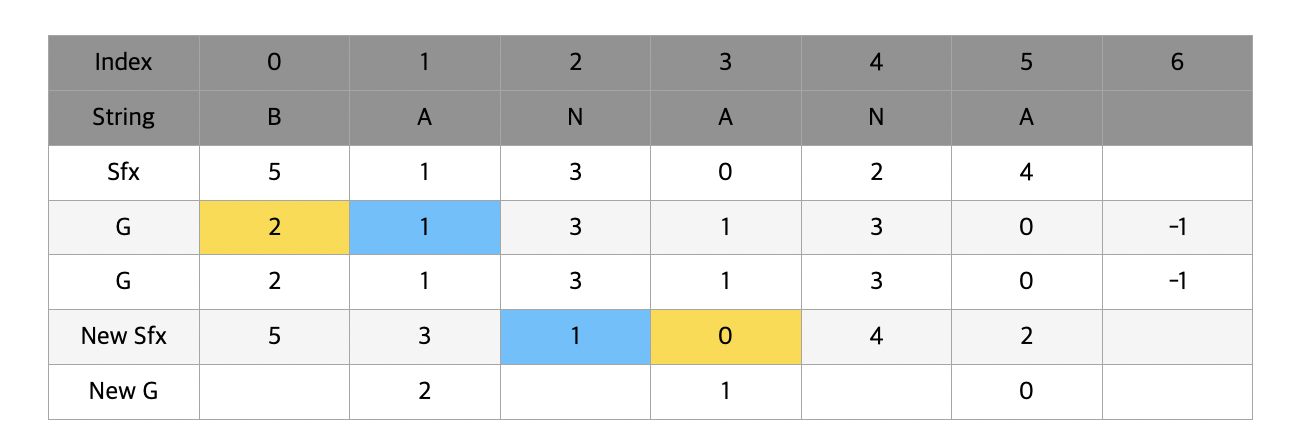
이번에는 g[3]과 g[0]을 비교하자. 길게 볼 필요 없이 g[3] < g[0]이기 때문에 new g[0] = new g[3] + 1이 된다. 여기서 g[3] < g[0] 이라는 것은 AN과 BA의 순위 관계를 매겨주기위해서 A < B 이기 때문에 첫번째 알파벳만을 확인해서 순위를 매겨줬다는 의미를 갖고있다는 것을 다시한번 확인하자.
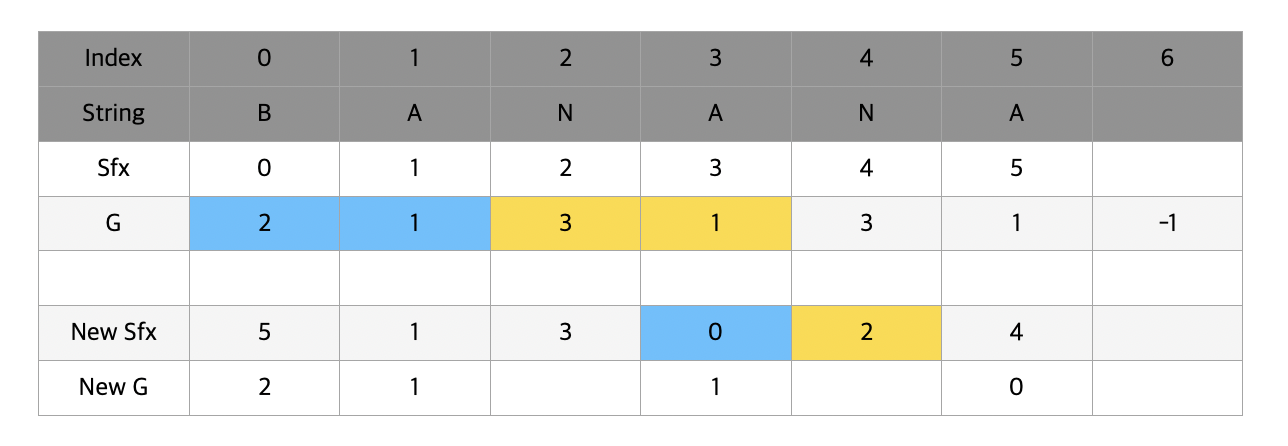
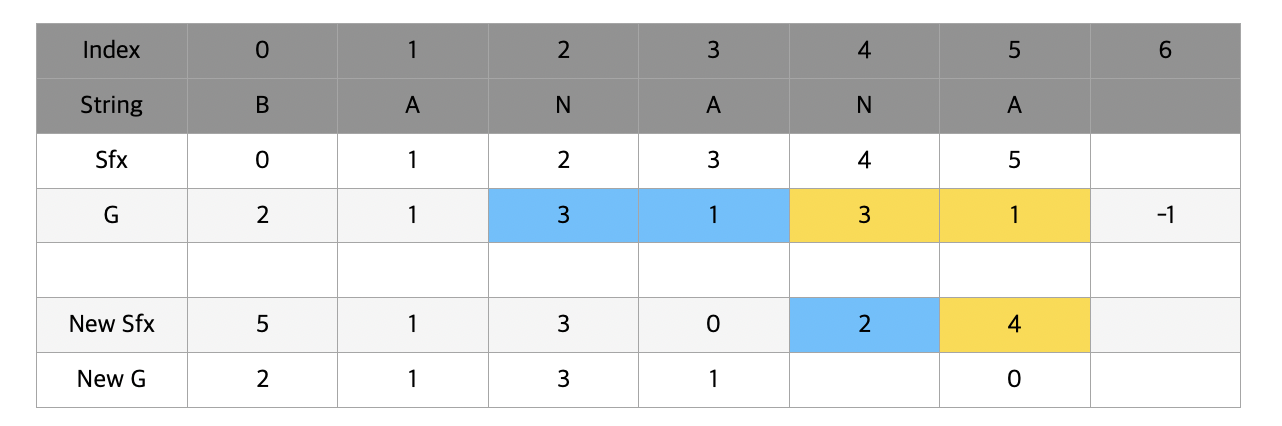
순서대로 나머지 빈칸들을 다 완성하면 새로운 sfx와 g값이 완성된다. t값도 2배를 해주어 1 -> 2로 변하였다.
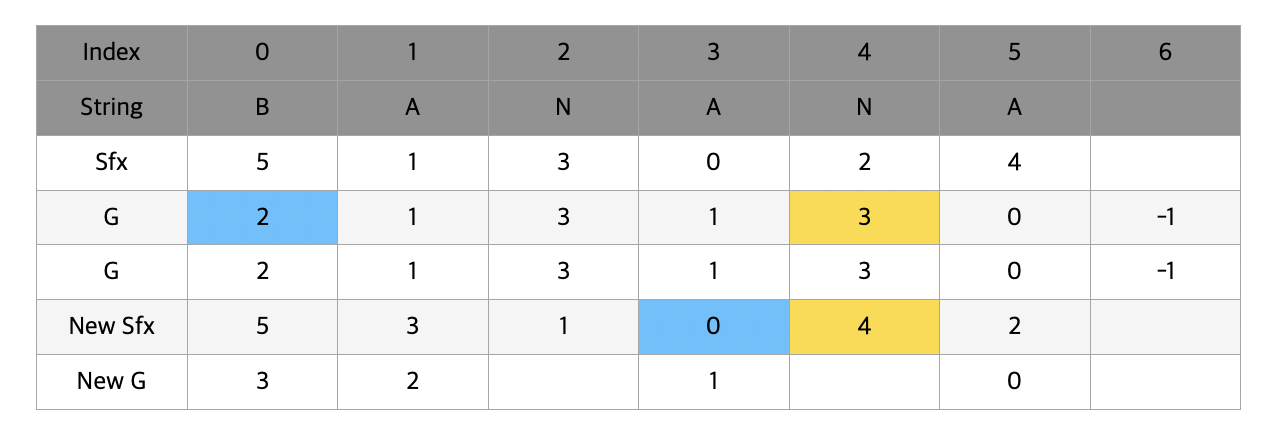
자 이제 sfx에는 문자 2개씩 비교해서 얻어낸 결과가 들어있고 g에는 문자열에서 해당 문자를 시작으로 2칸씩 묶었을 때 대소관계를 비교한 결과가 들어있다.
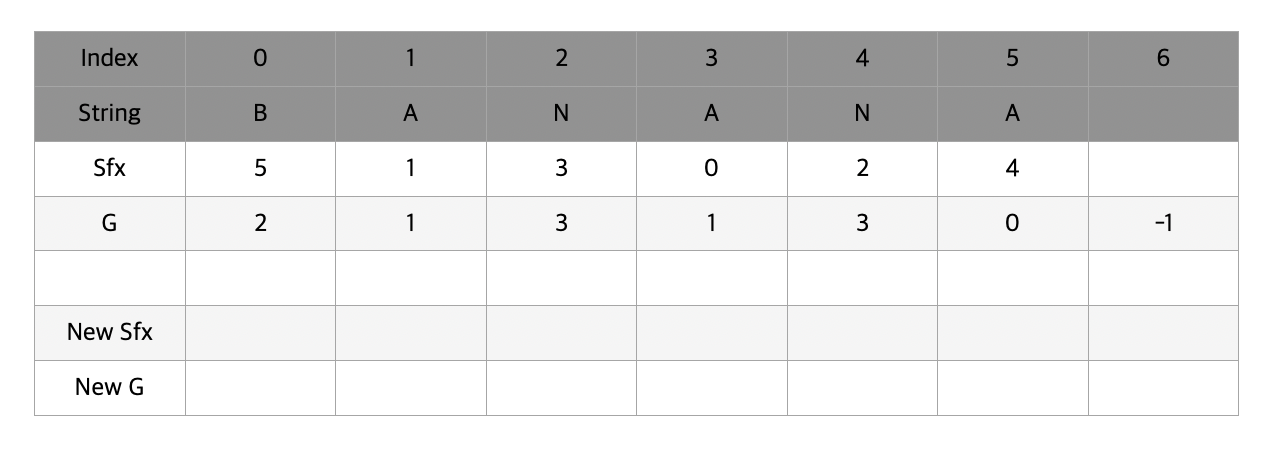
이제 다시 sfx배열을 g를 이용해서 정렬시켜줄 것이다. g에는 문자 2개씩 묶은 값이 들어있기 때문에 sfx는 최대 4개의 문자를 비교할 수 있게 된다.
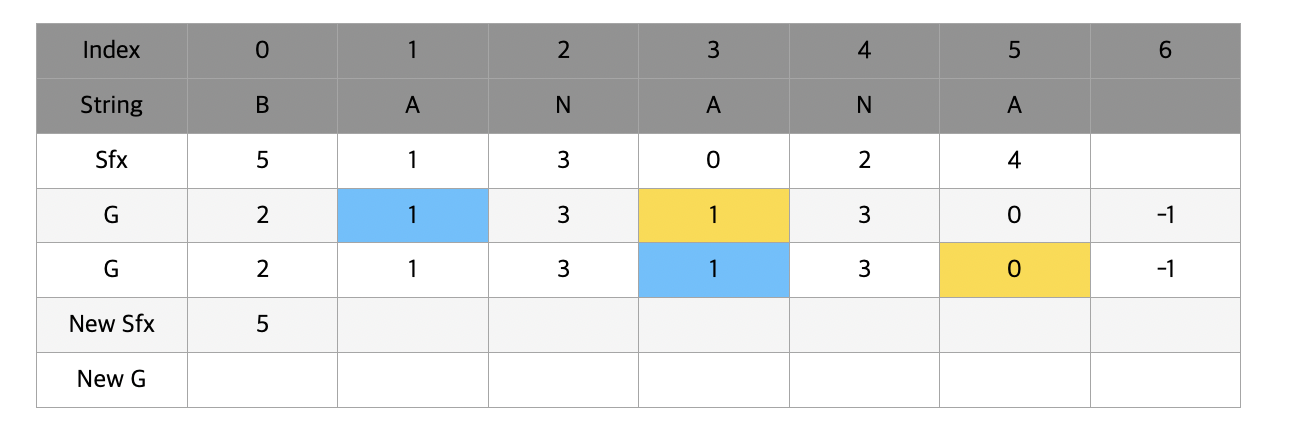
위와같이 ANAN과 ANA 를 비교해야할 때 처음 두 글자는 모두 AN으로 같기 때문에 뒤의 AN와 A 를 비교해서 순서를 매겨준다.
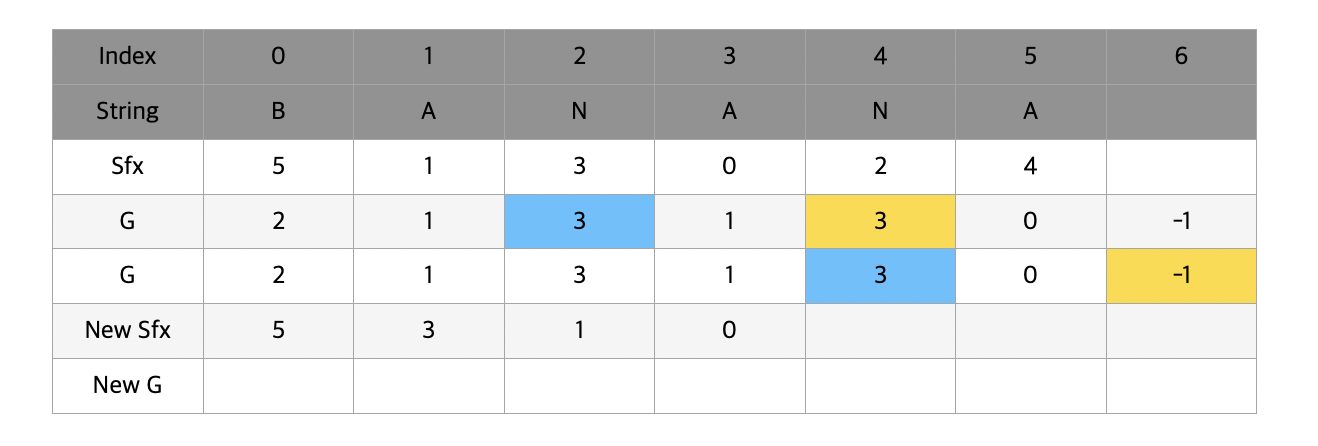
마찬가지로 NANA와 NA 를 비교해야한다면 첫 두 글자는 모두 NA로 같기 때문에 뒤의 NA와 (공백)을 비교해서 순서를 매겨준다.
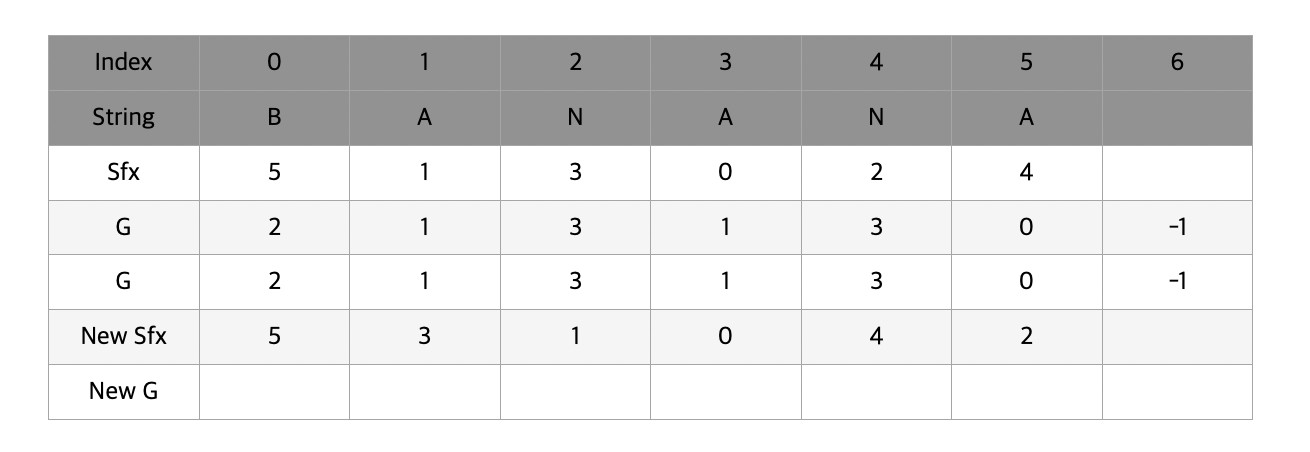
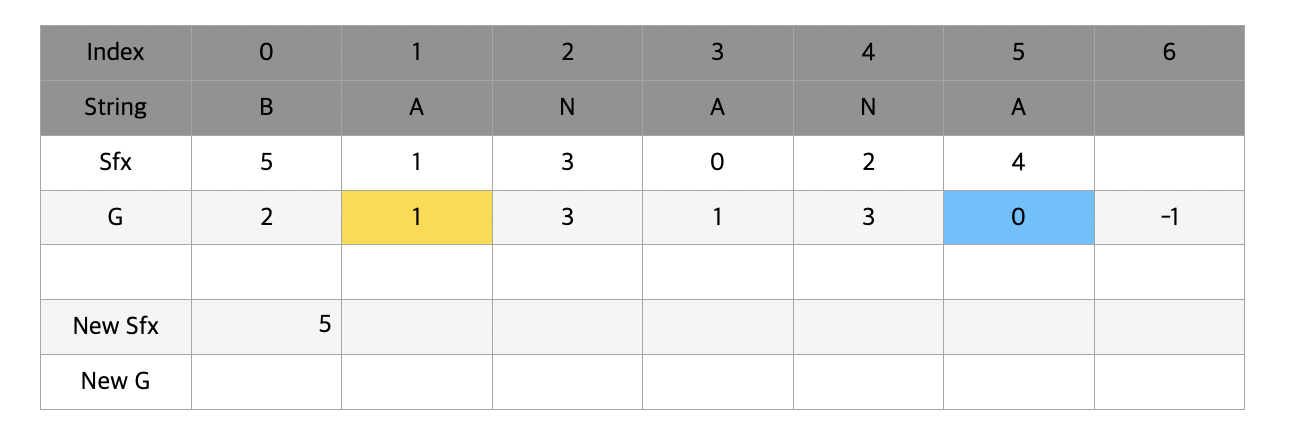
최종적으로 완성된 suffix array는 위와 같다. 이제 새로운 g를 마찬가지로 구해준다. 앞서 했던것과 과정은 동일한데 이번에는 t가 2이기 때문에 2칸 떨어져있는 곳의 g값을 참조한다는 것을 염두해두고 보길 바란다.
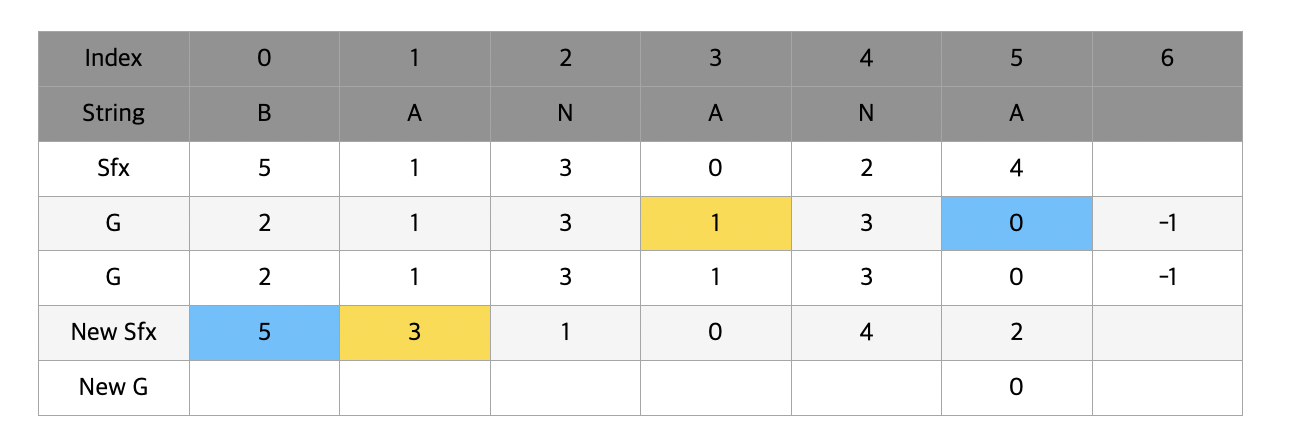
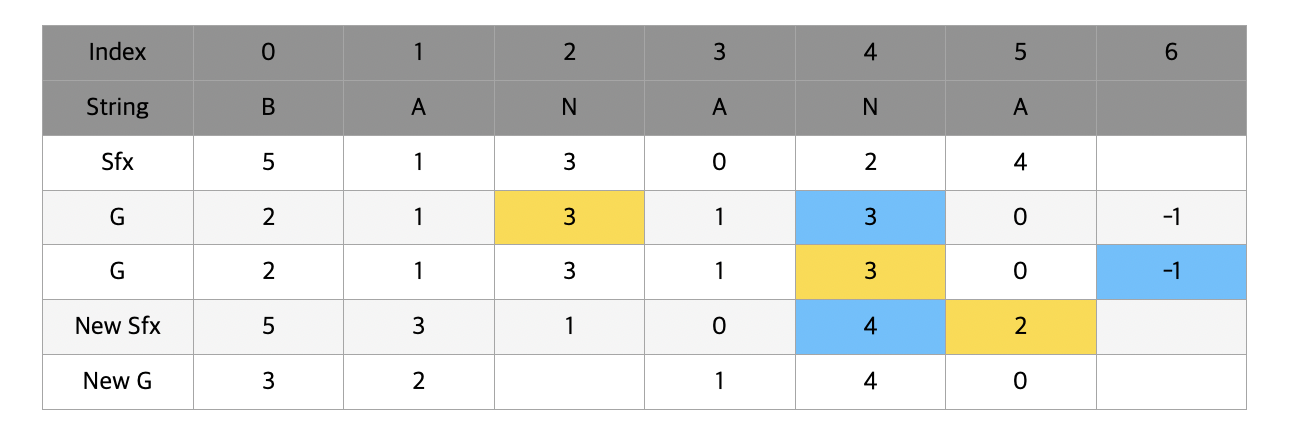
과정을 반복해 t가 n보다 커진다면 멈추고 그 때의 sfx를 반환시켜준다. 놀랍게도 n개의 알파벳을 모두 비교하던 때와는 다르게 단 2번의 비교만으로 n길이의 단어들을 비교할 수 있게 되었다.
따라서 O(logn)번 sfx sort를 하게되고 sort 자체에 O(nlogn)이 소요되고 비교과정이 O(1)으로 줄었기 때문에 총 O(nlog2n)의 시간복잡도를 갖게된다.
- Manber-Myers Function
func suffix(str: String) -> [Int] {
let n = str.count
var g = Array(repeating: -1, count: n+1)
var tmp = Array(repeating: -1, count: n+1)
var sfx = Array(repeating: 0, count: n)
var t = 1, idx = 0
func compare(i: Int, j: Int) -> Bool {
if g[i] == g[j] {
return g[i+t] < g[j+t]
}
else {
return g[i] < g[j]
}
}
for i in str.indices {
g[idx] = Int(str[i].asciiValue!)
sfx[idx] = idx
idx += 1
}
while t < n {
sfx.sort(by: compare)
tmp[sfx[0]] = 0
for i in 1..<n {
if compare(i: sfx[i-1], j: sfx[i]) {
tmp[sfx[i]] = tmp[sfx[i-1]]+1
}
else {
tmp[sfx[i]] = tmp[sfx[i-1]]
}
}
g = tmp
t <<= 1
}
return sfx
}
3. LCP (Longest Common Prefix)
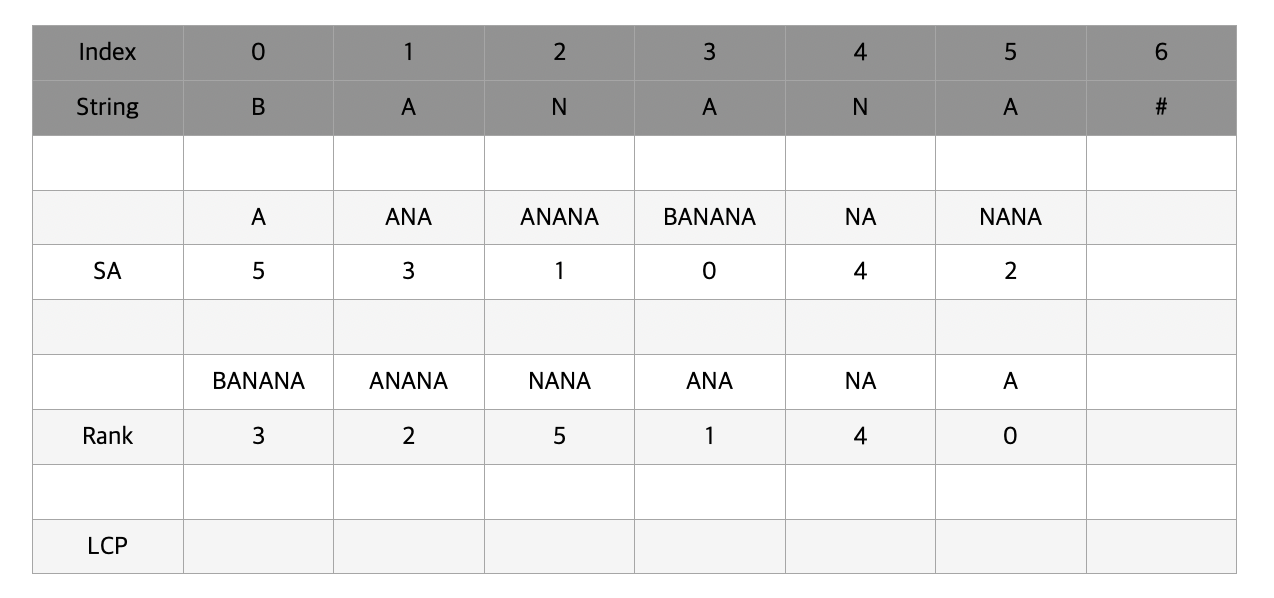
최장 공통 접두사를 의미하는 것으로 Suffix Array를 구한 후 바로 이전 suffix와의 lcp를 배열에 담은 것을 lcp array 라고 부른다. banana를 기준으로 [6, 4, 2, 1, 5, 3] 은 [a, ana, anana, banana, na, nana]를 나타내게 되고 lcp array를 구하면 [x, 1, 3, 0, 0, 2]가 되게 된다.
마찬가지로 일일히 이전 suffix와 현재 suffix를 앞에서부터 비교해나가면 o(n2)의 시간이 소요될 것이다. 자 이제 위에서 구한 suffix array를 활용할 때가 왔다. rank라는 배열을 하나 만들 것인데 이는 각각의 index로부터 시작하는 suffix의 suffix array(SA)상에서의 순위를 나타낸다.
rank와 SA를 나타내어 정리하면 다음 그림과 같다. banana는 SA상에서 3순위로 rank[0] = 3이 되었다.
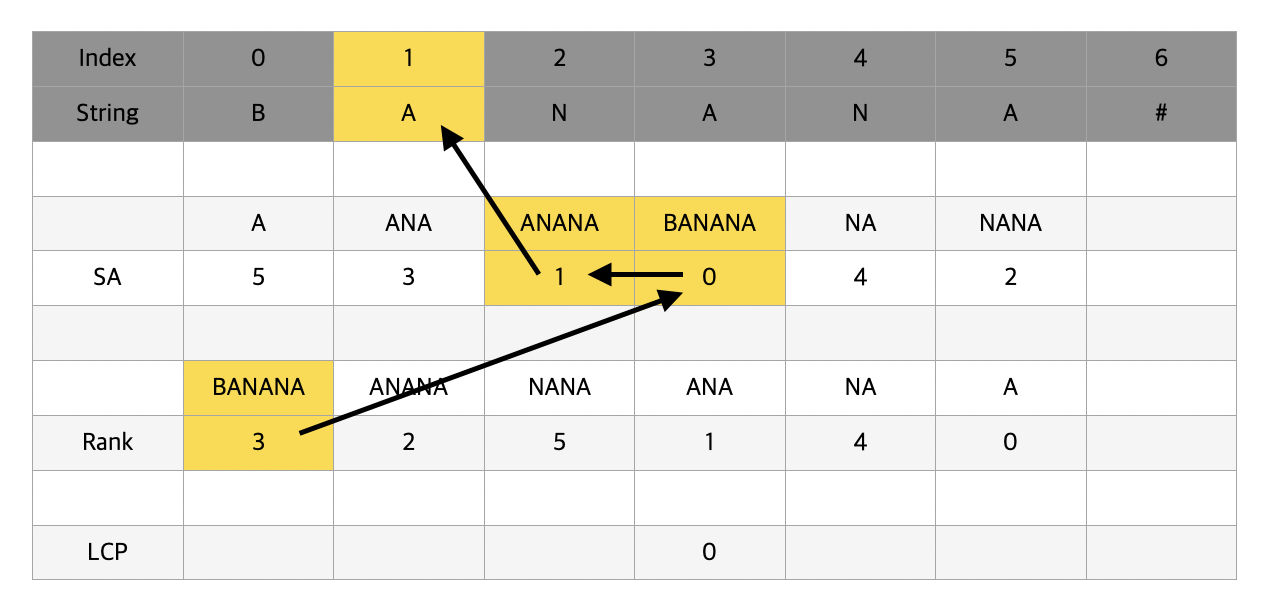
한가지 예시로 anana와 ana가 존재할 때 둘의 LCP는 ana로 길이 3이다. 그런데 맨앞에서 a를 둘 다 제거해보면 nana와 na가 나타나게 되고 둘의 LCP는 na로 길이 2이다.
anana와 ana은 suffix array 상에서 붙어있는데 맨 앞에서 a를 제거한 nana, na 역시 붙어있는 것은 suffix의 특성상 당연하다. 그렇다면 anana와 ana이 3이라는 공통 접두사가 존재하기 때문에 맨앞에서 한개씩 뗀 nana와 na 역시 최소 2 이상의 공통 접두사가 존재할 수 밖에 없다.
이제 banana부터 앞에서부터 하나씩 알파벳을 지워가면서 진행할 것이다. banana의 rank는 3으로 rank 2의 단어와 비교를 해야 LCP Array를 채울 수 있다. 이 때 SA[rank] 를 하게되면 해당 rank의 단어의 string상에서의 index를 알 수 있다. 따라서 banana와 anana를 비교할 수 있게 되고 둘은 공통 접두사가 없기 때문에 LCP[3] = 0 이 된다.
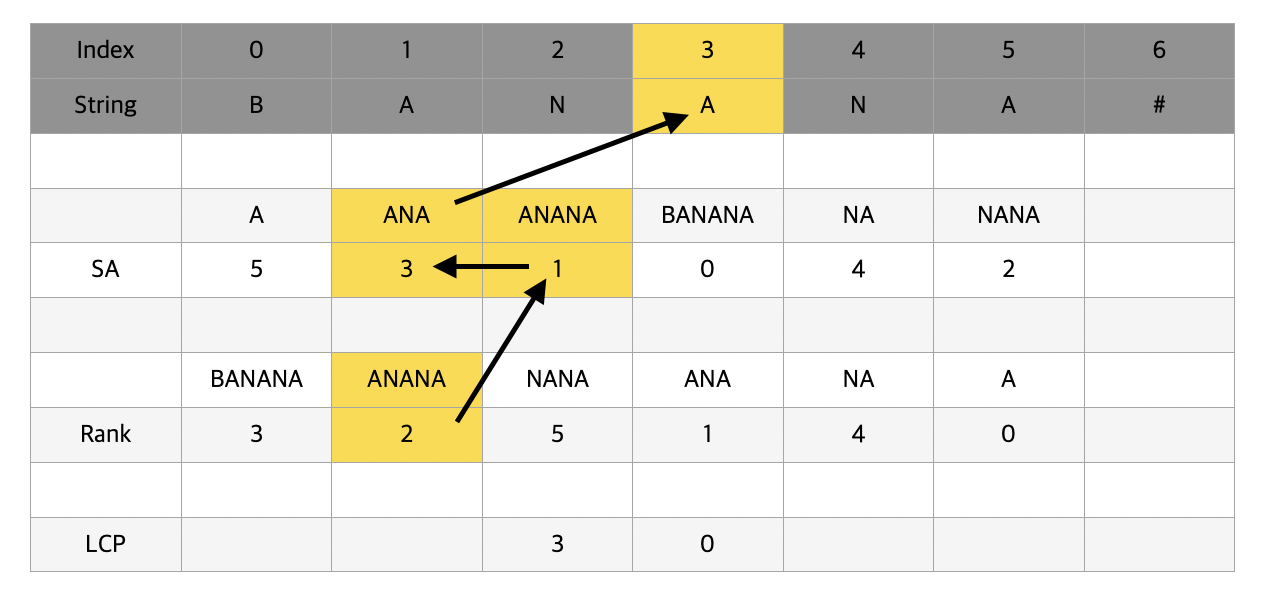
이번에는 anana의 차례이다. banana에서 anana가 됐지만 banana의 LCP 값이 0이었기 때문에 이전 정보를 활용하지 않는다. anana의 rank 값은 2고 바로 직전의 SA 값은 ana에 해당한다. anana와 ana는 공통 접두사 길이가 3이기 때문에 LCP[2] = 3이 된다.
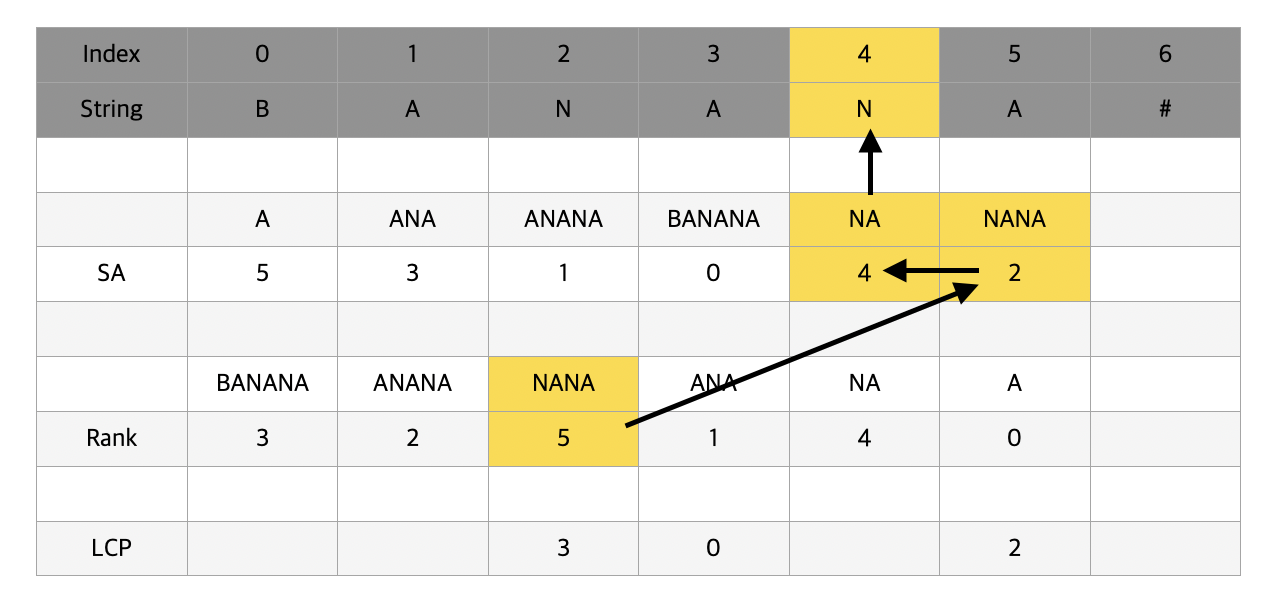
자 여기서부터가 하이라이트이다. anana에서 맨 앞 글자를 지우면 nana가 된다. 이 때 nana의 rank는 5로 rank 4인 na와 비교를 하게 된다.
그런데 이전에 구한 lcp 값 - 1보다 공통 접두사 길이가 크거나 같을 것이기 때문에 nana와 na를 맨앞글자부터 비교할 필요 없이 최소한 2글자는 공통된다는 것을 가정하여 3번째 글자끼리 비교를 하게 된다. 참고로 String에 #과 같은 안쓰는 문자를 추가해주어 문자열의 끝을 나타내주면 비교가 편하다.
이 때 세번째 글자는 같지 않기 때문에 공통 접두사의 길이는 2가 된다. 따라서 LCP[5] = 2가 된다. 이와같은 방법으로 나머지 모든 LCP를 완성하게 되면 [x, 1, 3, 0, 0, 2] 의 LCP 배열을 얻어낼 수 있다.
- LCP Code
let SA = suffix(str: str)
var rank = Array(repeating: 0, count: str.count)
var strArr = str.map{Character(String($0))}
strArr.append("#")
for i in 0..<str.count {
rank[SA[i]] = i
}
var len = 0
var LCP = Array(repeating: 0, count: str.count)
for i in 0..<str.count {
let k = rank[i]
if k != 0 {
while strArr[SA[k-1]+len] == strArr[i+len] {
len += 1
}
LCP[k] = len
if len > 0 {
len -= 1
}
}
}