동적 계획법
21 Jun 2021동적 계획법이란 주어진 문제를 해결하기 위해 여러 하위 문제들로 분할한 뒤 이를 합쳐서 문제를 해결하는 방식을 말한다. 이 때 하위 문제들의 결과를 배열같은 공간에 저장해주어 같은 연산을 여러번하지 않도록 하는 메모이제이션 기법이 같이 사용된다.
동적 계획법은 피보나치 수, LCI, LCS, Knapsack 등 다양한 문제에 활용되고 있으며 tech 파트 외에도 그래프나 자료구조, 수학 파트에서도 등장해 사용될 예정이므로 확실히 이해를 하고 넘어가는 것이 중요하다.
1. 피보나치 수
피보나치 수란 다음의 조건을 만족하는 수열을 의미한다.
F0 = 0, F1 = 1, Fn+2 = Fn+1 + Fn
이를 함수로 나타내면 다음과 같다.
func fibo(n: Int) -> Int {
if n == 1 || n == 2 {
return 1
}
return fibo(n: n-1) + fibo(n: n-2)
}
일반적으로 F10을 호출하게 되면 F9와 F8의 값이 필요하게 되고, 또 F9는 F8과 F7의 값이 필요하게 된다. 이 때 F8이 반복해서 나온다는 것을 알 수 있는데 계속해서 계산해보면 F8 밑에 있는 다른 값들 역시 여러 번 쓰인다는 것을 알 수 있다.
이 때 우리는 처음 계산할 때 그 결과를 저장해두고 다음번에 호출할 때 그 값을 불러 와서 쓰면 좋겠다는 생각을 할 수 있다. 이 발상에서 시작하여 주어진 문제를 하위 문제로 나누고 dp 배열을 활용하여 중복 연산을 줄이는 방법을 동적 계획법이라 부른다.
동적계획법에는 크게 top-down 방식과 bottom-up 방식이 있다.
1) Top-down 방식
var dp = Array(repeating: -1, count: MAXN)
func fibo(n: Int) -> Int {
if n == 1 || n == 2 {
return 1
}
if dp[n] != -1 {
return dp[n]
}
dp[n] = fibo(n: n-1) + fibo(n: n-2)
return dp[n]
}
주어진 식을 보면 알겠지만 기존의 재귀 호출방식에서 dp라는 배열이 추가된 것을 확인할 수 있다. 만약 해당 연산을 한번이라도 수행 했다면 해당 결과를 dp에 저장하고 이 후 연산 들에 대해서는 저장된 값을 불러와 해결하는 방식이다.
Top-down 방식은 점화식을 그대로 사용하면 되서 이해하기 쉽고 구현이 쉽다는 장점이 있지만 함수 호출이 여러번 이루어질시 약간의 overhead가 발생한다는 단점이 있다.
2) Bottom-up 방식
func fibo(n: Int) -> Int {
var a = 1, b = 0
for _ in 2...n {
let tmp = a
a = a+b
b = tmp
}
return a
}
Bottom-up 방식은 불필요한 함수 호출을 줄이기 위해서 가장 작은 문제부터 하나씩 쌓아가는 방식을 의미한다. Fn을 구하기 위해 F2부터 순서대로 F3, F4 … Fn순으로 구해나가는 것이 이에 해당한다.
2. LIS (Longest Increasing Subsequence)
LIS는 가장 긴 증가하는 부분 수열을 나타낸다. 증가하는 부분 수열이란 수열의 특정 부분을 지워 부분 수열을 만들때 앞에서부터 뒤로갈수록 값이 증가하는 형태를 띈 수열을 의미한다. 이 중 가장 길이가 긴 수열을 찾는 문제라고 할 수 있다.
1) O(n2) LIS
먼저 다음과 같은 수열이 있다고 생각해보자.
A = [1, 3, 5, 7, 2, 1, 4, 8]
i = 0 일때 A[0] = 1 이고 그 때의 dp값을 0로 설정하자.
그러면 i를 하나씩 증가 시켜갈때 점화식은 다음과 같다.
dp[i] = max(dp[j]) + 1, where A[j] < A[i]
이 경우 n개의 수열 값 각각에 대해 본인보다 작은 원소들을 모두 살펴봐야하므로 O(n2) 의 시간이 걸리게된다.
2) O(nlogn) LIS
위의 방법을 사용하면 본인보다 작은 index의 수열을 모두 살펴보는 것은 비효율적이란 생각이 든다. 그렇다면 dp에 A[i]를 포함하는 최장 부분 수열의 길이를 저장하는 것이 아닌 현재까지 이어온 최장 부분 수열의 A 값들을 저장해보자. 먼저 i = 0 부터 3까지를 보면 이전 값보다 현재값이 크기때문에 dp에는 다음과 같이 저장이 된다.
dp = [1, 3, 5, 7]
이제 i = 4 의 경우를 보자. 2의 경우 3보다 작고 1보다 큰 값이기 때문에 들어가야 할 위치는 1과 3 사이가 될 것이다. 이 때 1과 3 사이에 2를 집어넣는 것이 아닌 3 대신에 2를 덮어씌우는 방식을 사용한다. 그 결과는 다음과 같다.
dp = [1, 2, 5, 7]
왜 이런 방식을 사용하는 것인가 하면 1과 2로 이어지는 새로운 부분 수열을 우리가 만든다고 할 때 기존의 3, 5, 7은 2보다 큰 값이기 때문에 1과 2 사이에 위치할 수 없다. 따라서 매번 A[i]값이 들어갈 위치를 dp에서 찾아서 바꿔주고 그때의 dp의 index가 A[i]를 마지막 원소로 갖는 LIS의 길이가 된다. 이 때 dp 안에서 A[i]가 들어갈 위치를 찾는 것은 lower bound을 이용한다. 자세한 설명은 이분탐색 파트를 살펴보기 바란다.
모든 원소에 각각에 대해서 dp 안에 들어갈 위치를 찾으면 해결되는 문제로 총 nlogn의 시간이 소요된다. (Lower bound 탐색에 logn이 소요된다) 이 때 최종 결과로 나온 dp 배열은 LIS 수열이 아님을 명심하자. 중간에 삽입된 다른 값으로 대체가 되어 있을수도 있기 때문에 최장길이에 해당하는 A[i]부터 거꾸로 내려가면서 최장 수열을 찾아야한다.
let n = 7
var dp = Array(repeating: -1, count: n)
var A = [1, 3, 5, 7, 2, 4, 8]
dp[0] = A[0]
var dpCount = 1
for i in 1..<n {
let index = lowerBound(down: 0, up: dpCount, key: A[i], arr: dp)
if dp[index] == -1 {
dpCount += 1
}
dp[index] = A[i]
}
print(dpCount)
3. LCS (Longest Common Subsequence)
최장 공통 부분 수열이란 두 수열이 주어졌을 때 두개의 공통되는 부분 수열 중에서 가장 긴 것을 찾는 문제이다. 예를들어 ACAYKP 와 CAPCAK 의 LCS는 ACAK가 된다. 다음과 같은 2차원 LCS dp배열을 생각해보자.
| A | C | A | Y | K | P | |
|---|---|---|---|---|---|---|
| C | ||||||
| A | ||||||
| P | ||||||
| C | ||||||
| A | ||||||
| K |
CAPCAK순으로 왼쪽에서 오른쪽으로 배열을 채워 넣을 것이며 규칙은 다음과 같다.만약 두 문자가 일치할경우 row, col 모두 해당 문자를 뺀 부분까지의 LCS값에 1을 더한것이 구하고자 하는 dp 값일것이다.
if character same {
dp[row][col] = dp[row-1][col-1] + 1
}
else {
dp[row][col] = max(dp[row][col-1], dp[row-1][col])
}
결과는 다음과 같으며 dp[row.max][col.max]이 구하고자하는 LCS값이다.
| A | C | A | Y | K | P | |
|---|---|---|---|---|---|---|
| C | 0 | 1 | 1 | 1 | 1 | 1 |
| A | 1 | 1 | 2 | 2 | 2 | 2 |
| P | 1 | 1 | 2 | 2 | 2 | 3 |
| C | 1 | 2 | 2 | 2 | 2 | 3 |
| A | 1 | 2 | 3 | 3 | 3 | 3 |
| K | 1 | 2 | 3 | 3 | 4 | 4 |
let a = "ACAYKP".map{Character(String($0))}
let b = "CAPCAK".map{Character(String($0))}
var board:[[Int]] = Array(repeating: Array(repeating: 0, count: b.count+1), count: a.count+1)
for i in 1...a.count {
for j in 1...b.count {
if b[j-1] == a[i-1] {
board[i][j] = board[i-1][j-1] + 1
}
else {
board[i][j] = max(board[i][j-1], board[i-1][j])
}
}
}
print(board[a.count][b.count])
4. Knapsack
가방싸기 문제라고 불리는 knapsack은 가방의 최대 용량이 k라고 주어졌을 때 각 물건별로 무게와 가치가 주어지면 주어진 가방 용량 안에서 가치가 최대가 되도록 가방을 싸는 방법을 찾는 문제이다.
w라는 무게를 갖고 v라는 가치를 가지는 물건을 가방에 넣으려고 한다고하자. 생각해보면 w라는 무게를 넣고 싶다면 w만큼의 무게 자리를 확보해 준 후 그 때의 가치에서 v만큼을 더한것과 같다.
이를 점화식으로 나타내면 다음과 같다.
dp[i] = max(dp[i-w] + v, dp[i]) where i in w…k
var dp = Array(repeating: 0, count: k+1)
for wv in objects {
let w = wv.weight, v = wv.value
if w > k {continue}
var tmp = dp
for i in w...k {
if dp[i] < dp[i-w] + v {
tmp[i] = dp[i-w] + v
}
}
dp = tmp
}
print(dp[k])
5. 컨벡스 헐 트릭
동적 계획법에서 특정 점화식이 쓰였을 경우 시간을 획기적으로 줄여주는 기법. 컨벡스 헐을 구하는 것처럼 보이기 때문에 컨벡스 헐 트릭이란 이름이 붙었다. (컨벡스 헐에 대해서 몰라도 쓸 수 있지만 내용이 어려우므로 다른것 먼저 다뤄보고 공부하는 것을 추천한다)
DP[i] = min(A[i]∗B[j] + DP[j]) where j < i
이 함수를 우리는 직선방정식의 형태로 변화시킬 것이다. A[i] 를 x로 DP[i] 를 f(x)로 바꾸면 f(x) = B[j]∗x + dp[j] 와 같이 변한다. j에 따라 변하는 B[j] 와 dp[j]를 직선의 기울기와 절편으로 삼고 선분으로 표현하면 다음과 같다.
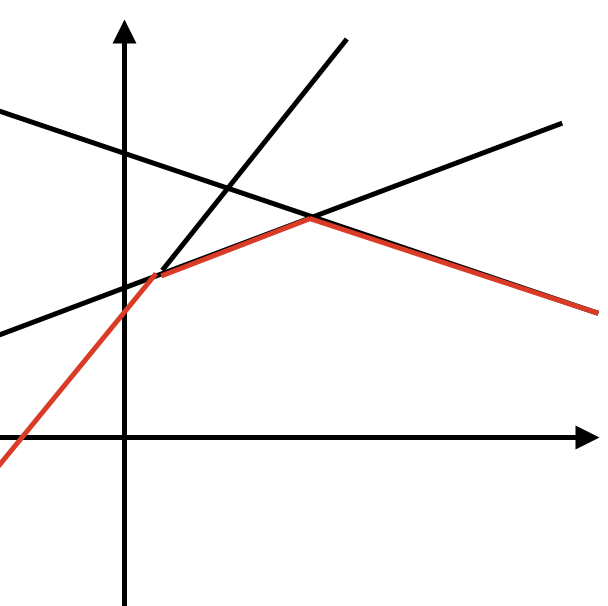
여기서 우리가 구하고자 하는 부분은 각 선분들 중 가장 아랫부분이다. 왜냐하면 구하고자하는 DP[i]는 여러 j에 대해 min값을 구하는 형태로 되어있기 때문이다.
j는 i보다 작거나 같은 값이기 때문에 i를 1씩 증가시키면서 DP[i]를 구할때마다 해당 결과를 이용해서 선분을 추가시켜주면 다음 i에 대해서 모든 j에 대한 선분들이 저장되어있을 것이기 때문에 문제를 간단히 풀 수 있다.
B[j] ≥ B[j+1]
이 때 위의 조건이 있다면 기울기가 점차 감소하는 형태이므로 이전 직선들과의 최하단 부분을 구하는데 용이하다. 다음 그림 세개를 보자.

먼저 새로운 직선과 이전 직선의 교점이 새로운 직선과 전전 직선의 교점보다 클 경우이다. 이 경우 이전 직선이 최하단 부분을 담당하는 곳이 있기 때문에 새로운 직선을 단순히 추가시켜주기만 하면 된다.
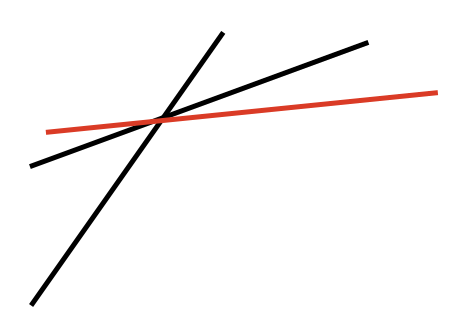
이 경우는 두 교점이 일치하는 경우이다. case에 따라서 이전 직선을 삭제할지 남겨둘지 정하면 된다.

이제 두 교점이 일치하는 경우에서 새로운 직선이 조금 아래로 내려온다고 생각해보자. 그러면 새로운 직선과 이전 직선의 교점이 새로운 직선과 전전 직선의 교점보다 왼쪽에 위치하는 것을 알 수 있다. 게다가 자세히 보면 최하단 부분을 구하는데에 이전 직선의 영향력이 아예 없어진 것을 알 수 있다. 이 경우 이전 직선을 직선 Set에서 제거시켜준다.
이렇게 최하단 직선 set를 구성했다면 우리가 원하는 x값에 대해서 이분탐색을 통해 어떤 직선을 써야하는지 찾아주고 그때의 dp값을 구해주면 O(nlogn) 만에 구할 수 있게 된다. 단 A[i] < A[i+1]라는 조건 있다면 새로운 입력의 적합한 직선은 이전에 사용한 직선 이후의 직선이 될것이기 때문에 이분탐색이 필요없어 O(n) 만에 문제를 해결할 수 있다.
6. 분할 정복 트릭
다음의 점화식을 만족하는 dp문제에 대해서 적용이 가능한 기법이다.
dp[i][j] = min(dp[i-1][k] + c[k][j]) (where k < j && c[i][j] is Monge Array)
Monge Array란 임의의 a ≤ b ≤ c ≤ d에 대해 C[a][c] + C[b][d] ≤ C[a][d] + C[b][c]를 만족하는 것을 의미한다. 그렇다면 임의의 p < q에 대해서 dp[i][p]가 최소가 되게하는 k인 optp는 dp[i][q]가 최소가 되게하는 k인 optq에 대해서 optp ≤ optq를 만족한다.
이를 통해 우리는 점화식을 찾을 때 연산 횟수를 상당부분 줄일 수 있게 된다. 원래대로라면 모든 i에 대해 모든 j를 살펴봐야하므로 O(n2) 가 걸려야하지만 O(nlogn) 까지 줄일 수 있게 된다. 이론만 보고서는 크게 이해가 안가는 파트니 꼭 문제를 풀어보고 이해하기 바란다.
7. 크누스 최적화
다음 세 조건을 만족하는 경우 크누스 최적화를 적용할 수 있다.
1. d[i][j] = min(d[i][k] + d[k][j]) + c[i][j] where i < k < j
2. c[a][c] + c[b][d] <= c[a][d] + c[b][c] where a<=b<=c<=d
3. c[b][c] <= c[a][d] where a<=b<=c<=d
이를 만족하면 A[i][j]가 d[i][j]가 답이 되도록 만드는 k의 위치(opt)라고 했을 때 A[i][j]는 다음을 만족한다.
A[i][j-1] ≤ A[i][j] ≤A[i+1][j]
이를 이용하여 d[i][j]를 구할 때 탐색 범위를 줄일 수 있고 속도를 향상 시킬 수 있다.
추천 문제
백준 1149 RGB거리
백준 2156 포도주 시식
백준 11054 가장 긴 바이토닉 부분 수열
백준 9251 LCS
백준 12865 평범한 배낭
백준 14751 Leftmost Segment
백준 13263 나무 자르기
백준 11001 김치
백준 13261 탈옥